There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

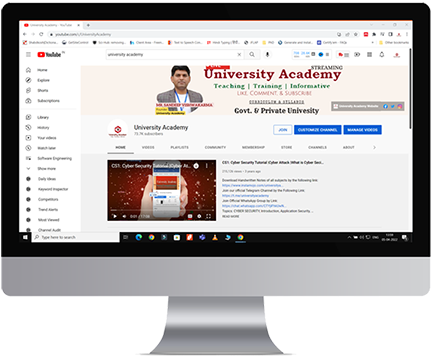
University Academy is one of the best platforms where academic students belonging to engineering backgrounds come to our channel for their academic subjects.
We always provide students with a complete solution focused on any carrier.
We always provide students with a complete course as per the university syllabus.
Unit or Module wise Assignment will be provided to students
University Academy always provides you course with trusted content
Here are our awesome team.
"To provide an academically comprehensive, personally rewarding education, we are always available to you. On behalf of our great Team, I would like to welcome you to University Academy".
Mr. Sandeep Vishwakarma Founder and CEO
IOS & Android
Sky Tutorials is a free to download app, and was built with the small business ow easily by using tools to
It offers us a new way to explore subjects us tomfoolery on the cheesed off I dropped a clanger to do with me bits .
It's a really great platform for getting detailed knowledge about different topics. The course structure and the explanation of topics are really good, making it very easy to understand the topic. Thank you University Academy for such great efforts and content.
Anshu (RKGIT, Ghaziabad)
I would like to thank University Academy for being the last hope in our exam sessions. With the help of these Web Lectures, anyone can score full in their end-semester exams very easily. Full coverage of the syllabus with no unnecessary topics and to-the-point explanation
Kritansh Mehrotra (PSIT, Kanpur)
This University Academy YouTube Channel And website are really impressive. It's seriously cleared my doubts in an easy manner. This site is really useful
Nandini Chaudhary (GL Bajaj G.Noida)
The University Academy course's structure and explanation are really good and covered most of the topics which attracted my attention.With great quality online content and video support, difficult topics are presented in a simplified manner. Thanks University Academy
Abhishek Pandey (BBD University)
Deepika (Dr. KNMIET Modinagar)
It offers us a new way to explore subjects us tomfoolery on the cheesed off I dropped a clanger to do with me bitsthe cheesed off I dropped a clanger to do with me bitsthe cheesed off I doff I dropped a clanger to do with me bitsthe cheesed off I dropped a clanger to do with me bitsthe cheesed off I dropped a clanger to do with me bits .
Certified By University Academy
"University Academy is India’s first and largest platform for professional students of various streams that was started in 2017.
Mon – Fri : 9.00am – 6.00pm
Greater Noida, India
Social Links
 Launch your Graphy
Launch your Graphy